Attention-based multi-modal robust cattle identification technique using deep learning
Prashant Digambar Pathak and Surya Prakash
Dept. of Computer Science & Engineering, Indian Institute of Technology Indore, Indore, 453552, India
Abstract
Conventional cattle identification techniques, such as ear tagging, tattooing, microchip embedding, notch-based, and electrical marking, have two main limitations. First, they are potentially distressing to animals. Second, they are susceptible to duplication or loss, which makes them unreliable. Over the past few years, research has revealed that cattle, much like humans, possess numerous unique biometric traits. Additionally, advancements in computing technology over the past decade have significantly enhanced innovations in digitizing animal biometrics. In this context, our study aims to investigate the amalgamation of multiple biometric modalities in cattle, using their face and muzzle patterns to establish a distinctive identification technique. Once cattle biometrics are digitized, they may find practical applications in resolving ownership assignment disputes, dealing with fraudulent insurance claims, and smart livestock management systems. It can also serve as a foundation for establishing regulatory compliance frameworks. The proposed technique in this paper presents a novel approach involving 1) precise detection of the face and muzzle by training the YOLOv8-based object detector, 2) feature extraction by fine-tuning the pre-trained deep convolutional neural network, 3) enhancing feature extraction by introducing spatial attention, 4) classification based on multi-modal features and 5) result analysis with various ablation studies and explainability with Grad-CAM. The proposed attention-based multi-modal identification technique incorporates both facial and muzzle cues and demonstrates a robust identification accuracy of 99.47% for muzzle features alone and a combined identification accuracy of 99.64% using both face and muzzle features.
Block Diagram
In the proposed technique, we have constructed a YOLOv8 based-object detector to extract the faces and muzzles from an image. Extracted faces and muzzles are then provided to two different feature extraction networks based on the modified EfficientNetV2B0 backbone (see Fig. 1). These models are fine-tuned to the last three layers with pre-trained weights of the ImageNet-1k dataset. Fig. 1 also highlights integration of spatial attention module which enhances our feature extraction backbone.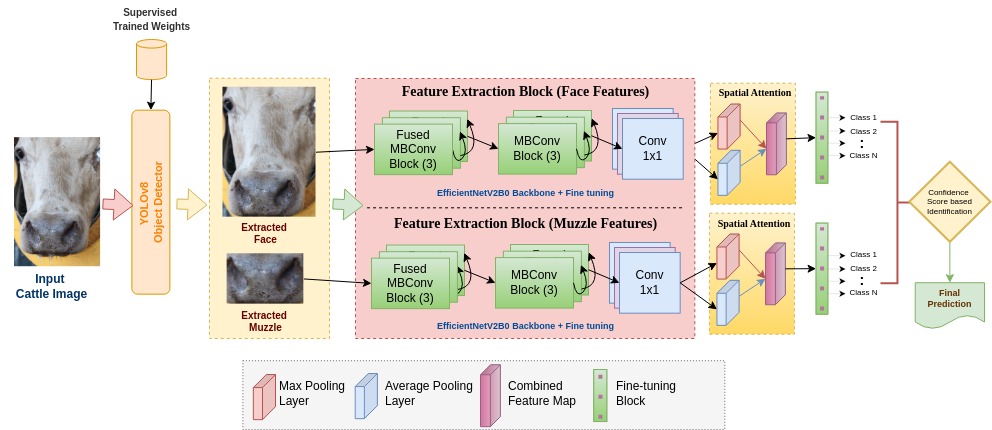
Procedure to test the proposed technique
In this section, we describe the procedure to test the deep learning model of the proposed technique, along with details about the datasets used in this study. Please follow the steps below to test the model:
- Set up the system with Python 3.10 and TensorFlow 2.12.
- Download the proposed model and datasets from the Kaggle links provided below.
- Assign the paths for the downloaded model and test datasets in the program.py file.
Kaggle links:
- Model trained on CMPD300 Muzzle dataset: [Download here]
- CMPD300 Muzzle dataset: [Download here]
- Model trained on CMPD300 Face dataset: [Download here]
- CMPD300 Face dataset: [Download here]
- Model trained on CMPD268 Muzzle dataset: [Download here]
- CMPD268 Muzzle dataset: [Download here]
- Model trained on CMPD568 Muzzle dataset: [Download here]
- CMPD568 Muzzle dataset: [Download here]
Alternatively, you can log in to Kaggle and execute the proposed models directly on the platform without the need for local setup. This approach offers the advantage of utilizing Kaggle's computational resources, eliminating the necessity to configure your own system. The required datasets have been hosted on Kaggle and are readily accessible for integration with the models. Simply follow these steps:
- Log in or create an account on Kaggle.
- Navigate to the shared Kaggle project containing the proposed models and datasets.
- Muzzle identification network on CMPD300 dataset: [Click here]
- Face identification network on CMPD300 dataset: [Click here]
- Muzzle identification network on CMPD268 dataset: [Click here]
- Muzzle identification network on CMPD568 dataset: [Click here]
- Open the project notebook or script provided with the models.
- Run the code cells within Kaggle's interactive environment, which is pre-configured with Python and TensorFlow support.
© Prashant Digambar Pathak and Surya Prakash